Tasks and Applications#
DDSP audio synthesis has found application in a diversity of domains and downstream tasks. Most of the literature falls under the domain music, speech, or singing voice synthesis. However, recent work has also explored sound effect synthesis []. We note that while singing voice could be considered a subtask of music, there are significant enough differences in implementation and connection to speech synthesis such that we decided to include it as a separate domain.
In this section we’ll go over the more common synthesis tasks related to DDSP audio synthesis, focusing on providing an introduction to music and singing voice synthesis. For a more comprehensive account of tasks and applications, see our recent review on the topic [HSF+23].
Tasks Overview#
Here is an overview of the most common synthesis tasks that DDSP has been used for. Related tasks across domains are listed along the horizontal with a brief decsription of the task.
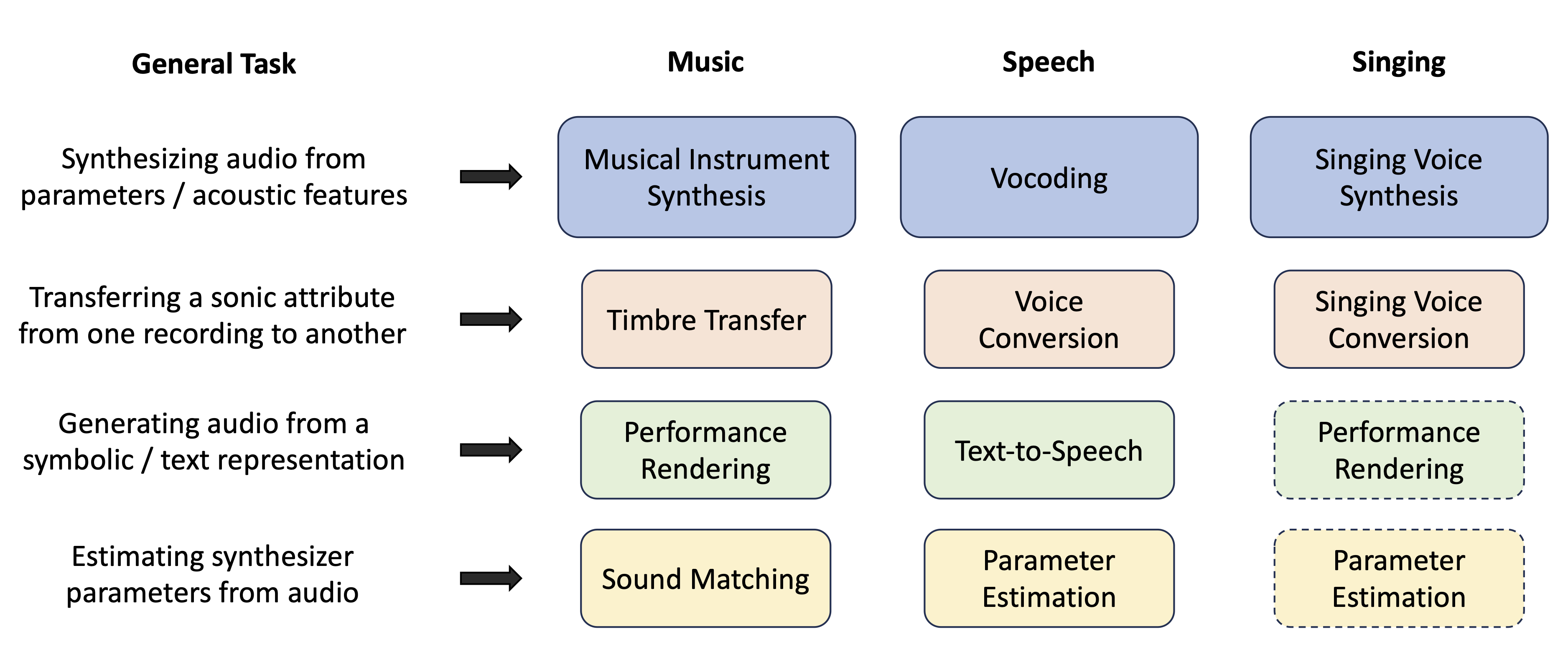
Fig. 4 Overview of tasks that DDSP audio synthesis has found application. Boxes with a dashed outline indicate that this tasks have yet to be explored within the DDSP literature, as far as we are aware.#
In this tutorial we’ll focus on music and singing domains, although we encourage interested readers to explore the related speech synthesis literature. Many of the techniques used in speech synthesis are applicable to musical audio (and certainly singing voice) synthesis, and vice-versa.
Musical Instrument Synthesis#
The primary task in DDSP audio synthesis for musical audio synthesis has revolved around the modeling of instruments. The goal is to use a differentiable digital synthesizer to accurately model the tones of a target instrument using a data-driven approach. For example, the original DDSP work by Engel et al. [EHGR20] implemented a sinusoidal modelling synthesizer [SS90] differentiably and trained a neural network to predict synthesizer parameters from audio features The input audio features included fundamental frequency, loudness, and mel-frequency cepstral coefficents (MFCCs). They trained this neural network using recordings of instrumental performances, including violin performances.
Subsequent to the differentiable sinusoidal modelling synthesizer by Engel et al., a number of other digital synthesis methods have been explored within a differentiable paradigm including waveshaping synthesis [HSF21], frequency modulation synthesis [CMS22, YXT+23], and wavetable synthesis [SHC+22]. The design of the synthesizers mentioned thus far are particularly well-suited for modelling of monophonic and harmonic instruments. This is in part due to the use of explicit pitch detection and harmonically constrained differentiable synthesizers, which adds a useful inductive bias towards the generation of these sounds.
How about polyphonic or non-harmonic sounds?
While these sounds are more challenging to model for a number of reasons (which we’ll start to investigate further in this tutorial), some research has been conducted in this direction. Renault et al. [RMR22] explored polyphonic generation for piano synthesis and Caillon and Esling [CE21] used a hybrid approach combining neural audio synthesis with DDSP for polyphonic generation. Synthesis of non-harmonic rigid-body percussion sounds was explored by Diaz et al. [DHS+23].
Let’s look at how differentiable musical instrument synthesizers have been applied to other creative tasks.
Timbre Transfer#
Timbre transfer is related to the style transfer task in the image domain, which aims to apply the style of one image or artist to a target image [GEB15]. In musical timbre transfer the goal is to apply the timbre from one instrument to the performance of another. For example, we might try to replicate a trumpet performance but have it sound like it was played on a violin. This task is related to singing voice conversion, discussed below.
The synthesis approach proposed by [EHGR20] naturally lends itself to this task. Fundamental frequency \(f_0\) and loudness envelopes are explicitly presented to the model which then predicts the timbre via time-varying harmonic amplitudes. Timbre is essentially encoded in the weights of the neural network during training. A model trained on violin performances can then be used for many-to-one timbre transfer by providing \(f_0\) and loudness envelopes from a new source instrument.

Fig. 5 Screen shot of the tone transfer website. Accessed November 1, 2023.#
You can try this out for yourself online using Google’s ToneTransfer. Details on the development of this web app can be read in the paper by Carney et al. [CLT+21].
Performance Rendering#
The task of performance rendering extends a musical instrument synthesis through the prediction of synthesis parameters from symbolic notation (e.g., MIDI). This involves not only correctly representing musical attributes such as pitch, dynamics, and rhythm, but also capturing the expressive performance elements. An example of a recent performance rendering system by Wu et al. [WMD+22] augmented Engel et al.’s differentiable sinusoidal modelling synthesizer with a neural network front-end to predict synthesis parameters from MIDI.
Sound Matching#
Sound matching is the inverse problem of determining optimal parameters for a synthesizer to match a target audio sample. Prior to DDSP, solutions using neural networks were limited to supervised training on a parameter loss (i.e., using a synthetic dataset where correct synthesizer parameters are known). Masuda and Saito [MS23] proposed a differentiable subtractive synthesizer for sound matching, allowing for an audio loss function to be used and enabling training on out-of-domain sounds.
Singing Voice Synthesis#
Singing voice synthesis (SVS) in the context of DDSP is the task of generating realistic singing audio from input audio features. It draws from both speech synthesis and musical instrument synthesis. The synthesizer in SVS is often referred to as a vocoder, which is the term used within the speech literatue for a synthesizer. The musical context of SVS imposes further challenges including emphasis on pitch and rhythmic accuracy, more expressive pitch and loudness contours, and a demand for higher resolution results (i.e., higher sampling rate).
One of the first DDSP vocoders designed for SVS was SawSing by Wu et al. [WHY+22], who proposed a differentiable source-filter approach using a sawtooth waveform for the excitation signal. Subsequent work on SVS has also explored a differentiable source-filter method and include Yu and Fazekas [YF23], who used differentiable linear predictive coding (LPC) and wavetables, and Nercessian [Ner23], who proposed a differentiable WORLD vocoder.
Singing Voice Conversion#
Singing voice conversion (SVC) is the task of transorming a recording of one singer such that it sounds like it was sung by a different target sing. It is related to both timbre transfer of musical instruments and voice conversion in speech synthesis. In addition to maintaining the intelligibility of the sung lyrics, SVC systems must contend with the dynamic pitch contours and expressivity present in singing voices. In the DDSP literature this task was explored by Nercessian [Ner23], who applied their differentiable WORLD vocoder to the task of SVC using a decoder conditioned on a speaker-independent embedding. Another notable example of DDSP-based SVC is in the results of the 2023 SVC Challenge Huang et al. [HVL+23], which reported strong performance from DSPGan [SZL+23], a hyrbid model that uses a DDSP vocoder to generate input features for a generative adversarial vocoder.
Summary#
In this section we presented a brief overview of some of the main applications and tasks that DDSP audio synthesis has been applied to, focusing on the domains of music and singing. Each domain includes a main synthesis task which involves generating audio from input acoustic features. Timbre transfer in music and singing voice conversion in singing voice synthesis is the task of transforming a performance such that it sounds like it was performed on another instrument or sung by another singer, respectively. In the music domain we also introduced performance rendering and synthesizer sound matching.
References#
- CE21
Antoine Caillon and Philippe Esling. RAVE: A variational autoencoder for fast and high-quality neural audio synthesis. December 2021. arXiv [Preprint]. Available at https://doi.org/10.48550/arXiv.2111.05011 (Accessed 2022-03-08). URL: http://arxiv.org/abs/2111.05011 (visited on 2022-03-08), arXiv:2111.05011.
- CLT+21
Michelle Carney, Chong Li, Edwin Toh, Ping Yu, and Jesse Engel. Tone Transfer: In-Browser Interactive Neural Audio Synthesis. In Joint Proceedings of the ACM IUI 2021 Workshops. 2021.
- CMS22
Franco Caspe, Andrew McPherson, and Mark Sandler. DDX7: Differentiable FM Synthesis of Musical Instrument Sounds. In Proceedings of the 23rd International Society for Music Information Retrieval Conference. 2022.
- DHS+23
Rodrigo Diaz, Ben Hayes, Charalampos Saitis, György Fazekas, and Mark Sandler. Rigid-body sound synthesis with differentiable modal resonators. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
- EHGR20(1,2)
Jesse Engel, Lamtharn (Hanoi) Hantrakul, Chenjie Gu, and Adam Roberts. DDSP: Differentiable Digital Signal Processing. In 8th International Conference on Learning Representations. April 2020.
- GEB15
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. A Neural Algorithm of Artistic Style. Journal of Vision, 16(12):326, 2015. doi:10.1167/16.12.326.
- HSF21
Ben Hayes, Charalampos Saitis, and György Fazekas. Neural Waveshaping Synthesis. In Proceedings of the 22nd International Society for Music Information Retrieval Conference. Online, November 2021.
- HSF+23
Ben Hayes, Jordie Shier, György Fazekas, Andrew McPherson, and Charalampos Saitis. A Review of Differentiable Digital Signal Processing for Music & Speech Synthesis. August 2023. arXiv:2308.15422, doi:10.48550/arXiv.2308.15422.
- HVL+23
Wen-Chin Huang, Lester Phillip Violeta, Songxiang Liu, Jiatong Shi, and Tomoki Toda. The Singing Voice Conversion Challenge 2023. July 2023. arXiv [Prerint]. Available at https://doi.org/10.48550/arXiv.2306.14422 (Accessed 2023-07-25). arXiv:2306.14422.
- MS23
Naotake Masuda and Daisuke Saito. Improving Semi-Supervised Differentiable Synthesizer Sound Matching for Practical Applications. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:863–875, 2023. doi:10.1109/TASLP.2023.3237161.
- Ner23(1,2)
Shahan Nercessian. Differentiable WORLD Synthesizer-Based Neural Vocoder With Application To End-To-End Audio Style Transfer. In Audio Engineering Society Convention 154. May 2023. URL: https://www.aes.org/e-lib/browse.cfm?elib=22073 (visited on 2023-06-21).
- RMR22
Lenny Renault, Rémi Mignot, and Axel Roebel. Differentiable Piano Model for Midi-to-Audio Performance Synthesis. In Proceedings of the 25th International Conference on Digital Audio Effects, 8. Vienna, Austria, 2022.
- SS90
Xavier Serra and Julius Smith. Spectral Modeling Synthesis: A Sound Analysis/Synthesis System Based on a Deterministic Plus Stochastic Decomposition. Computer Music Journal, 14(4):12–24, 1990. URL: www.jstor.org/stable/3680788 (visited on 2019-12-21), doi:10.2307/3680788.
- SHC+22
Siyuan Shan, Lamtharn Hantrakul, Jitong Chen, Matt Avent, and David Trevelyan. Differentiable Wavetable Synthesis. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4598–4602. May 2022. ISSN: 2379-190X. URL: http://arxiv.org/abs/2111.10003 (visited on 2022-03-12), doi:10.1109/ICASSP43922.2022.9746940.
- SZL+23
Kun Song, Yongmao Zhang, Yi Lei, Jian Cong, Hanzhao Li, Lei Xie, Gang He, and Jinfeng Bai. DSPGAN: A Gan-Based Universal Vocoder for High-Fidelity TTS by Time-Frequency Domain Supervision from DSP. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. June 2023. doi:10.1109/ICASSP49357.2023.10095105.
- WHY+22
Da-Yi Wu, Wen-Yi Hsiao, Fu-Rong Yang, Oscar Friedman, Warren Jackson, Scott Bruzenak, Yi-Wen Liu, and Yi-Hsuan Yang. DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation. In Proceedings of the 23rd International Society for Music Information Retrieval Conference, 76–83. 2022.
- WMD+22
Yusong Wu, Ethan Manilow, Yi Deng, Rigel Swavely, Kyle Kastner, Tim Cooijmans, Aaron Courville, Cheng-Zhi Anna Huang, and Jesse Engel. MIDI-DDSP: Detailed control of musical performance via hierarchical modeling. In International Conference on Learning Representations. 2022. URL: https://openreview.net/forum?id=UseMOjWENv.
- YXT+23
Zhen Ye, Wei Xue, Xu Tan, Qifeng Liu, and Yike Guo. NAS-FM: Neural Architecture Search for Tunable and Interpretable Sound Synthesis based on Frequency Modulation. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, 5869–5877. 2023. doi:10.24963/ijcai.2023/651.
- YF23
Chin-Yun Yu and György Fazekas. Singing voice synthesis using differentiable lpc and glottal-flow-inspired wavetables. arXiv preprint arXiv:2306.17252, 2023.