Speech Decomposition with Source Filter Model#
In this example, we’re going to decompose a speech signal into its source \(e[n]\) and filter components \(a_k\), following the LPC model (6) we introduced in the section Differentiable Implementation of IIR Filters.
We’ll first use the traditional method to estimate the LPC filter, and then we’ll use our differentiable LPC to do end-to-end decomposition.
Again, let’s first import the necessary packages and define some helper functions.
Show code cell source
import torch
import torch.nn.functional as F
import torchaudio
import math
import numpy as np
from torchaudio.functional import lfilter
import matplotlib.pyplot as plt
from typing import Optional, Tuple, List, Union
from IPython.display import Audio
import diffsptk
/home/runner/.local/lib/python3.12/site-packages/vector_quantize_pytorch/vector_quantize_pytorch.py:436: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
@autocast(enabled = False)
/home/runner/.local/lib/python3.12/site-packages/vector_quantize_pytorch/vector_quantize_pytorch.py:621: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
@autocast(enabled = False)
/home/runner/.local/lib/python3.12/site-packages/vector_quantize_pytorch/finite_scalar_quantization.py:134: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
@autocast(enabled = False)
/home/runner/.local/lib/python3.12/site-packages/vector_quantize_pytorch/lookup_free_quantization.py:165: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
@autocast(enabled = False)
Show code cell source
def plot_t(
title: str,
ys: List[np.ndarray],
labels: List[str] = None,
scatter: bool = False,
axhline: bool = False,
x_label: str = "Samples",
y_label: str = "Ampitude",
):
for y, label in (
zip(ys, labels) if labels is not None else zip(ys, [None] * len(ys))
):
plt.plot(y, label=label) if not scatter else plt.scatter(
np.arange(len(y)) + 1, y, label=label
)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.title(title)
if label is not None:
plt.legend()
if axhline:
plt.axhline(y=0, color="r", linestyle="dashed", alpha=0.5)
def plot_f(
ys: List[np.ndarray] = None,
paired_ys: List[Tuple[np.ndarray, np.ndarray]] = None,
ys_labels: List[str] = None,
paired_ys_labels: List[str] = None,
sr: int = None,
):
if ys is not None:
for y, label in (
zip(ys, ys_labels) if ys_labels is not None else zip(ys, [None] * len(ys))
):
plt.magnitude_spectrum(
y, Fs=sr, scale="dB", window=np.hanning(len(y)), label=label
)
if paired_ys is not None:
for (f, y), label in (
zip(paired_ys, paired_ys_labels)
if paired_ys_labels is not None
else zip(paired_ys, [None] * len(paired_ys))
):
plt.plot(f, 20 * np.log10(np.abs(y)), label=label)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Magnitude (dB)")
plt.xlim(20, sr // 2)
plt.title("Frequency spectrum")
if ys_labels is not None or paired_ys_labels is not None:
plt.legend()
We’re going to use a speech sample from the CMU Arctic speech synthesis database.
!wget "http://festvox.org/cmu_arctic/cmu_arctic/cmu_us_awb_arctic/wav/arctic_a0007.wav"
Show code cell output
--2025-06-30 21:30:42-- http://festvox.org/cmu_arctic/cmu_arctic/cmu_us_awb_arctic/wav/arctic_a0007.wav
Resolving festvox.org (festvox.org)...
199.4.150.153
Connecting to festvox.org (festvox.org)|199.4.150.153|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 128044 (125K) [audio/x-wav]
Saving to: ‘arctic_a0007.wav’
arctic_a0007.wav 0%[ ] 0 --.-KB/s
arctic_a0007.wav 100%[===================>] 125.04K --.-KB/s in 0.008s
2025-06-30 21:30:43 (15.1 MB/s) - ‘arctic_a0007.wav’ saved [128044/128044]
Show code cell source
y, sr = torchaudio.load("arctic_a0007.wav")
y = y.squeeze()
plt.plot(np.arange(y.shape[0]) / sr, y.numpy())
plt.xlabel("Time [s]")
plt.ylabel("Amplitude")
plt.show()
Audio(y.numpy(), rate=sr)
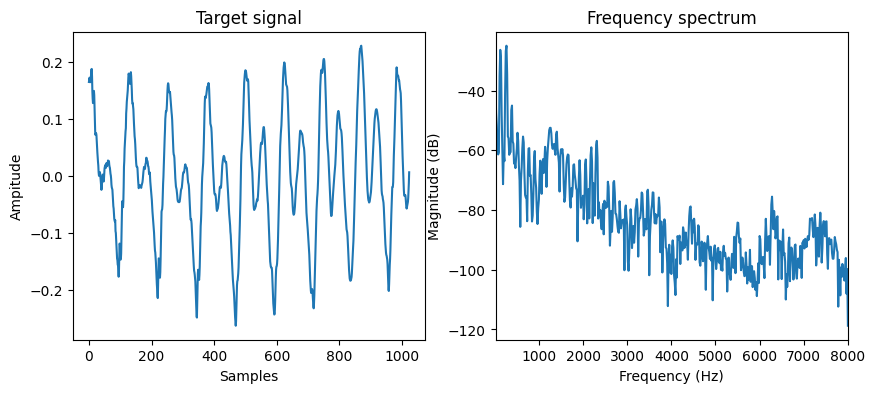
Let’s pick up one short segment from the speech, with relatively static pitch and formants for a stationary model.
Show code cell source
target = y[10000:11024]
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("Target signal", [target.numpy()])
plt.subplot(1, 2, 2)
plot_f([target.numpy()], sr=sr)
plt.show()
Classic LPC Estimation#
The common way to estimate the LPC filter is assuming the current sample \(s[n]\) can only be approximated from past samples. This results in minimising the prediction error \(e[n]\):
Its least squares solution can be computed from the autocorrelation of the signal [Mak75]. We’ll use the diffsptk package to compute this.
lpc_order = 18
frame_length = 1024
lpc = diffsptk.LPC(lpc_order, frame_length)
gain, coeffs = lpc(target).split([1, lpc_order], dim=-1)
print(f"Gain: {gain.item()}")
Gain: 0.23411035537719727
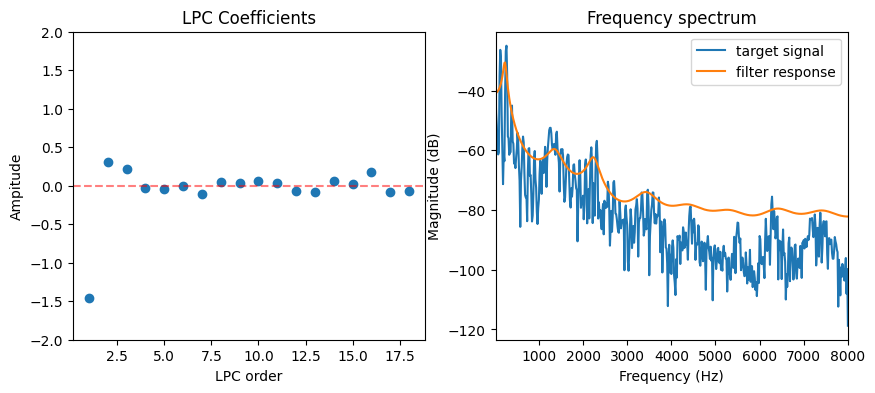
If we plot the spectrum of the LPC filter, we’d see that it approximates the spectral envelope of the signal.
Show code cell source
freq_response = (
gain
/ torch.fft.rfft(torch.cat([coeffs.new_ones(1), coeffs]), n=frame_length)
/ frame_length
)
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("LPC Coefficients", [coeffs.numpy()], scatter=True, axhline=True, x_label="LPC order")
plt.ylim(-2, 2)
plt.subplot(1, 2, 2)
plot_f(
ys=[target.numpy()],
ys_labels=["target signal"],
paired_ys=[
(
np.arange(frame_length // 2 + 1) / frame_length * sr,
freq_response.numpy(),
)
],
paired_ys_labels=["filter response"],
sr=sr,
)
plt.show()
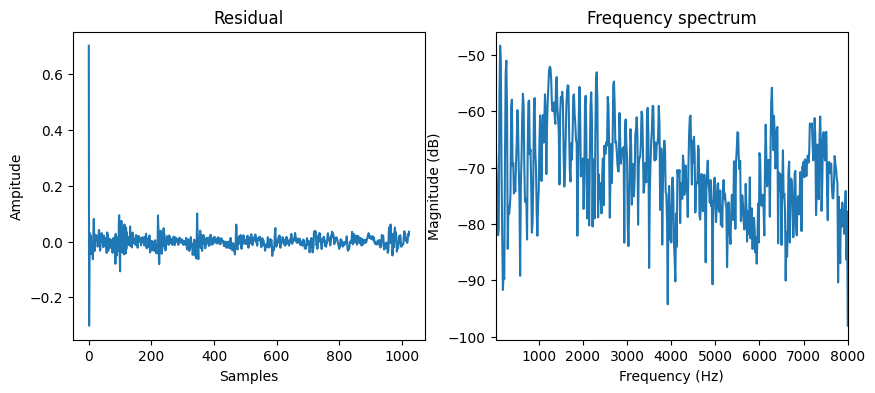
We can get the source (or residual) \(e[n]\) by inverse filtering the signal with the LPC coefficients, which is equivalent to the filtering the signal with a FIR filter \([1, -a_1, -a_2, \dots, -a_M]\).
e = (
target
+ F.conv1d(
F.pad(target[None, None, :-1], (lpc_order, 0)), coeffs.flip(0)[None, None, :]
).squeeze()
)
e = e / gain
After cancelling the spectral envelope, the frequency response of the residual becomes flatter and has very equal energy across the spectrum. This is a result of the least squares optimisation, which assumes that the prediction error is white noise.
Show code cell source
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("Residual", [e.numpy()])
plt.subplot(1, 2, 2)
plot_f([e.numpy()], sr=sr)
plt.show()
Decomposing Speech with Differentiable LPC and a Glottal Flow Model#
In the above example, we have very little assumptions about the source \(e[n]\). We only assume that it is whilte-noise like. In the next example, we’re going to incorporate a glottal flow model to give more constraints to the source.
The model we’re going to use is the transformed-LF [Fan95] model, which models the periodic vibration of the vocal folds. Specifically, we’re using the derivative of the glottal flow model, which combines the glottal flow with lips radiation by assuming lips radiation is a first-order differentiator. This model has only one parameter \(R_d\), which is strongly correlated with the perceived vocal effort. Although the model is differentiable, for computational efficiency, we’re going to use a pre-computed lookup table to approximate the model.
Show code cell source
def transformed_lf(Rd: torch.Tensor, points: int = 1024):
# the implementation is adapted from https://github.com/dsuedholt/vocal-tract-grad/blob/main/glottis.py
# Ra, Rk, and Rg are called R parameters in glottal flow modeling
# We can infer the values of Ra, Rk, and Rg from Rd
Rd = torch.as_tensor(Rd).view(-1, 1)
Ra = -0.01 + 0.048 * Rd
Rk = 0.224 + 0.118 * Rd
Rg = (Rk / 4) * (0.5 + 1.2 * Rk) / (0.11 * Rd - Ra * (0.5 + 1.2 * Rk))
# convert R parameters to Ta, Tp, and Te
# Ta: The return phase duration
# Tp: Time of the maximum of the pulse
# Te: Time of the minimum of the time-derivative of the pulse
Ta = Ra
Tp = 1 / (2 * Rg)
Te = Tp + Tp * Rk
epsilon = 1 / Ta
shift = torch.exp(-epsilon * (1 - Te))
delta = 1 - shift
rhs_integral = (1 / epsilon) * (shift - 1) + (1 - Te) * shift
rhs_integral /= delta
lower_integral = -(Te - Tp) / 2 + rhs_integral
upper_integral = -lower_integral
omega = torch.pi / Tp
s = torch.sin(omega * Te)
y = -torch.pi * s * upper_integral / (Tp * 2)
z = torch.log(y)
alpha = z / (Tp / 2 - Te)
EO = -1 / (s * torch.exp(alpha * Te))
t = torch.linspace(0, 1, points + 1)[None, :-1]
before = EO * torch.exp(alpha * t) * torch.sin(omega * t)
after = (-torch.exp(-epsilon * (t - Te)) + shift) / delta
return torch.where(t < Te, before, after).squeeze()
Show code cell source
t = torch.linspace(0, 1, 1024)
plt.plot(t, transformed_lf(0.3).numpy(), label="Rd = 0.3")
plt.plot(t, transformed_lf(0.5).numpy(), label="Rd = 0.5")
plt.plot(t, transformed_lf(0.8).numpy(), label="Rd = 0.8")
plt.plot(t, transformed_lf(2.7).numpy(), label="Rd = 2.7")
plt.title("Transformed LF")
plt.legend()
plt.xlabel("T (period)")
plt.ylabel("Amplitude")
plt.show()

Show code cell source
# 0.3 <= Rd <= 2.7 is a reasonable range for Rd
# we sampled them logarithmically for better resolution at lower values
table = transformed_lf(torch.exp(torch.linspace(math.log(0.3), math.log(2.7), 100)))
# align the peaks of the transformed LF for better optimisation
peaks = table.argmin(dim=-1)
shifts = peaks.max() - peaks
aligned_table = torch.stack(
[torch.roll(table[i], shifts[i].item(), 0) for i in range(table.shape[0])]
)
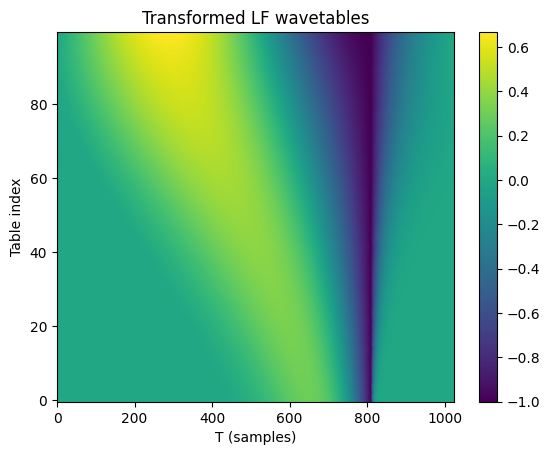
plt.title("Transformed LF wavetables")
plt.imshow(aligned_table, aspect="auto", origin="lower")
plt.xlabel("T (samples)")
plt.ylabel("Table index")
plt.colorbar()
plt.show()
The full model we’re going to use is:
We replace source \(e[n]\) with the following parameters: gain \(g\), fundamental frequency \(f_0\), phase offset \(\phi\), and \(R_d\). \(w\) is the pre-computed glottal flow model, and \(f_s\) is the sampling rate. Let’s define this model in code.
class SourceFilter(torch.nn.Module):
def __init__(
self,
lpc_order: int,
sr: int,
table_points=1024,
num_tables=100,
init_f0: float = 100.0,
init_offset: float = 0.0,
init_log_gain: float = 0.0,
):
super().__init__()
Rd_sampled = torch.exp(torch.linspace(math.log(0.3), math.log(2.7), num_tables))
table = transformed_lf(Rd_sampled, points=table_points)
peaks = table.argmin(dim=-1)
shifts = peaks.max() - peaks
aligned_table = torch.stack(
[torch.roll(table[i], shifts[i].item(), 0) for i in range(table.shape[0])]
)
self.register_buffer("table", aligned_table)
self.register_buffer("Rd_sampled", Rd_sampled)
self.f0 = torch.nn.Parameter(torch.tensor(init_f0))
self.offset = torch.nn.Parameter(torch.tensor(init_offset))
self.Rd_index_logits = torch.nn.Parameter(torch.zeros(1))
self.log_gain = torch.nn.Parameter(torch.tensor(init_log_gain))
# we use the reflection coefficients parameterisation for stable optimisation
self.log_area_ratios = torch.nn.Parameter(torch.zeros(lpc_order))
self.logits2lpc = torch.nn.Sequential(
diffsptk.LogAreaRatioToParcorCoefficients(lpc_order),
diffsptk.ParcorCoefficientsToLinearPredictiveCoefficients(lpc_order),
)
self.lpc_order = lpc_order
self.table_points = table_points
self.num_tables = num_tables
self.sr = sr
@property
def Rd_index(self):
return torch.sigmoid(self.Rd_index_logits) * (self.num_tables - 1)
@property
def Rd(self):
return self.Rd_sampled[torch.round(self.Rd_index).long().item()]
@property
def gain(self):
return torch.exp(self.log_gain)
@property
def filter_coeffs(self):
return self.logits2lpc(
torch.cat([self.log_gain.view(1), self.log_area_ratios])
).split([1, self.lpc_order])
def source(self, steps):
"""
Generate the gloottal pulse source signal
"""
# select the wavetable using linear interpolation
select_index_floor = self.Rd_index.long().item()
p = self.Rd_index - select_index_floor
selected_table = (
table[select_index_floor] * (1 - p) + table[select_index_floor + 1] * p
)
# generate the source signal by interpolating the wavetable
phase = (
torch.arange(
steps, device=selected_table.device, dtype=selected_table.dtype
)
/ self.sr
* self.f0
+ self.offset
) % 1
phase_index = phase * self.table_points
# append the first sample to the end for easier interpolation
padded_table = torch.cat([selected_table, selected_table[:1]])
phase_index_floor = phase_index.long()
phase_index_ceil = phase_index_floor + 1
p = phase_index - phase_index_floor
glottal_pulse = (
padded_table[phase_index_floor] * (1 - p)
+ padded_table[phase_index_ceil] * p
)
return glottal_pulse
def forward_filt(self, e):
"""
Apply the LPC filter to the input signal
"""
# get filter coefficients
log_gain, lpc_coeffs = self.filter_coeffs
# IIR filtering
b = log_gain.new_zeros(1 + lpc_coeffs.shape[-1])
b[0] = torch.exp(log_gain)
a = torch.cat([lpc_coeffs.new_ones(1), lpc_coeffs])
return lfilter(e, a, b, clamp=False)
def forward(self, steps):
"""
Generate the speech signal
"""
return self.forward_filt(self.source(steps))
def inverse_filt(self, s):
"""
Inverse filtering
"""
# get filter coefficients
_, lpc_coeffs = self.filter_coeffs
e = (
s
+ F.conv1d(
F.pad(s[None, None, :-1], (self.lpc_order, 0)),
lpc_coeffs.flip(0)[None, None, :],
).squeeze()
)
e = e / self.gain
return e
Proper initialisation of the parameters plays an important role in the optimisation. We’re going to use the following initialisation.
model = SourceFilter(lpc_order, sr, init_f0=130.0, init_offset=0.0, init_log_gain=-1.3)
print(f"Gain: {model.gain.item()}")
print(f"Rd: {model.Rd.item()}")
print(f"f0: {model.f0.item()}")
print(f"Offset: {model.offset.item() % 1}")
Gain: 0.27253180742263794
Rd: 0.9100430011749268
f0: 130.0
Offset: 0.0
Show code cell source
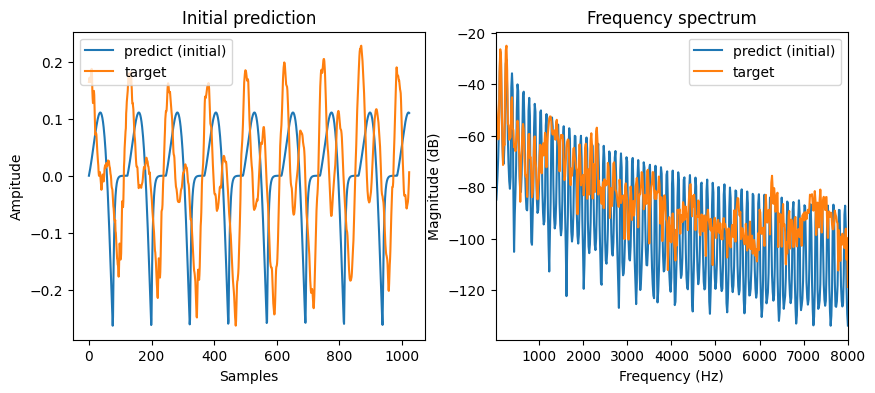
with torch.no_grad():
output = model(1024)
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("Initial prediction", [output.numpy(), target.numpy()], labels=["predict (initial)", "target"])
plt.subplot(1, 2, 2)
plot_f(
ys=[output.numpy(), target.numpy()],
ys_labels=["predict (initial)", "target"],
sr=sr,
)
plt.show()
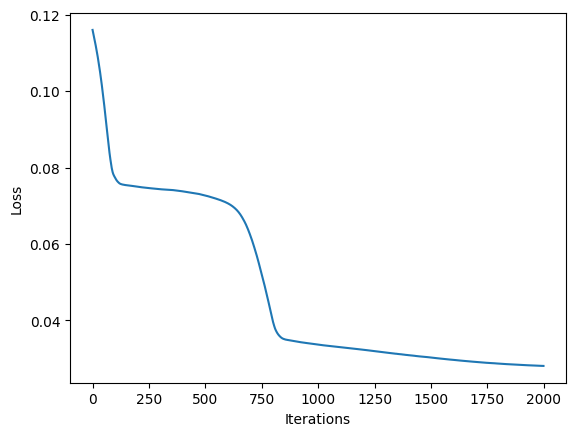
Let’s optimise the parameters with gradient descent. We’re going to use the famous Adam optimiser with a learning rate of 0.001 and run it for 2000 iterations. The loss function we’re going to use is the L1 loss between the original signal and the modelled signal.
Show code cell source
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
losses = []
for _ in range(2000):
optimizer.zero_grad()
output = model(1024)
loss = F.l1_loss(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
plt.plot(losses)
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.show()
Show code cell source
with torch.no_grad():
final_output = model(1024)
print(f"Gain: {model.gain.item()}")
print(f"Rd: {model.Rd.item()}")
print(f"f0: {model.f0.item()}")
print(f"Offset: {model.offset.item() % 1}")
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("Final prediction", [final_output.numpy(), target.numpy()], labels=["predict (optimised)", "target"])
plt.subplot(1, 2, 2)
plot_f(
ys=[final_output.numpy(), target.numpy()],
ys_labels=["predict (optimised)", "target"],
sr=sr,
)
plt.show()
Gain: 0.1844010055065155
Rd: 1.5502203702926636
f0: 131.02639770507812
Offset: 0.9482988640666008
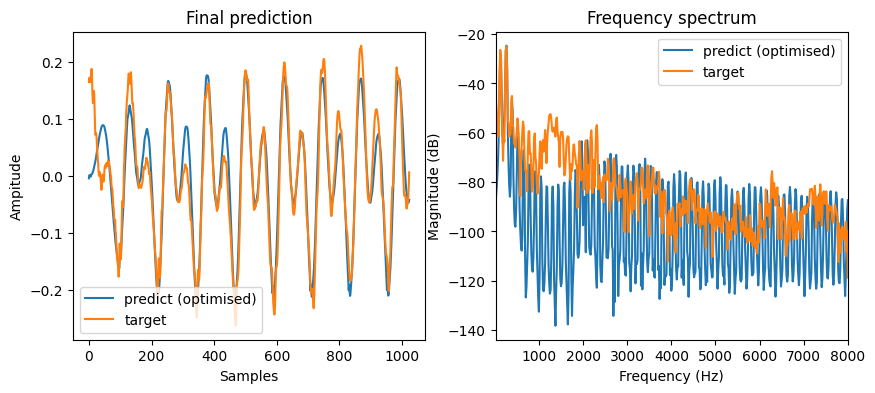
Wow, this is pretty good! We can see that the model reconstructs the original signal quite well with very similar waveforms. Moreover, the model tells what are the optimal parameters to construct the source signal. Let’s see what is the source signal looks like.
Show code cell source
with torch.no_grad():
e = model.source(1024)
s = model.forward_filt(e)
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t("Waveform", [e.numpy() / 4, s.numpy()], labels=["e[n]", "s[n]"])
plt.subplot(1, 2, 2)
plot_f(
ys=[e.numpy() / 4, s.numpy()],
ys_labels=["e[n]", "s[n]"],
sr=sr,
)
plt.show()
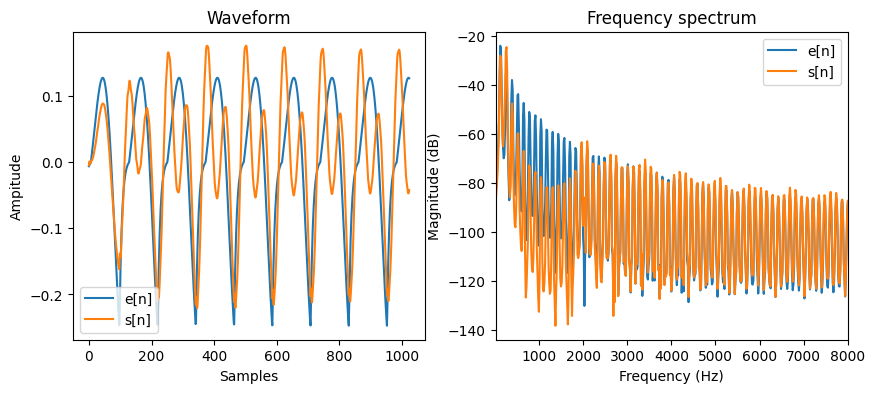
Let’s compare the spectrum of the two filters.
Show code cell source
_, lpc_coeffs = model.filter_coeffs
with torch.no_grad():
freq_response_opt = (
model.gain
/ torch.fft.rfft(
torch.cat([lpc_coeffs.new_ones(1), lpc_coeffs]), n=frame_length
)
/ frame_length
)
fig = plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plot_t(
"LPC Coefficients",
[coeffs.numpy(), lpc_coeffs.detach().numpy()],
labels=["least squares LPC", "differentiable LPC"],
scatter=True,
axhline=True,
x_label="LPC order",
)
plt.ylim(-2, 2)
plt.subplot(1, 2, 2)
freqs = np.arange(frame_length // 2 + 1) / frame_length * sr
plot_f(
paired_ys=[
(
freqs,
freq_response.numpy(),
),
(
freqs,
freq_response_opt.numpy(),
),
],
paired_ys_labels=["least squares LPC", "differentiable LPC"],
sr=sr,
)
plt.show()
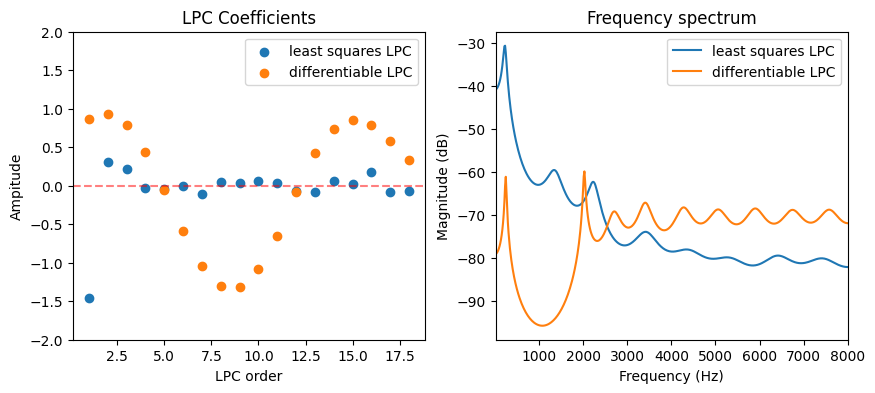
Interestingly, the two filters looks very different. The biggest reason is because we restricted the source signal to have specific shapes. The gradient method also can not achieve a lossless decomposition, while the classic LPC method can. However, the source signal we get from the gradient method is much more interpretable. In fact, the latter method is a simplified version of the synthesiser used in GOLF vocoder proposed by Yu et al. [YF23].
References#
- Fan95
Gunnar Fant. The lf-model revisited. transformations and frequency domain analysis. Speech Trans. Lab. Q. Rep., Royal Inst. of Tech. Stockholm, 2(3):40, 1995.
- Mak75
John Makhoul. Linear prediction: a tutorial review. Proceedings of the IEEE, 63(4):561–580, 1975.
- YF23
Chin-Yun Yu and György Fazekas. Singing voice synthesis using differentiable lpc and glottal-flow-inspired wavetables. arXiv preprint arXiv:2306.17252, 2023.